长陡立文模子越来越能"记",但实在让它们跑到线上时,开端顶不住的常常不是算力,而是KV Cache。
每生成一个新 token,模子都要回读越来越长的历史 Key 和 Value。陡立文越长、batch 越大,KV Cache 对显存容量和显存带宽的挥霍就越彰着。
这亦然为什么 KV Cache 量化成了长陡立文 serving 的中枢问题:压得不够,显存撑不住;压得太狠,推理质地又容易崩。

Together AI、悉尼大学和 UIUC 的接头团队,为此建议了一种面向果然 serving 的 2-bit KV Cache 量化决议——OSCAR。
模子不再仅仅把 K/V 张量压小,而是围绕 attention 实在会使用的标的来作念旋转、编著和分组,让量化舛误尽量闪避模子最敏锐的部分。
在约 2.28 effective bits per KV element 的预算下,OSCAR 仍能接近 BF16;在 Qwen3-4B-Thinking 上,比拟全层 3-bit K/V TurboQuant,最高提高 40.1 分。
这意味着,KV Cache 压缩不再仅仅"少占显存",而是初始投入果然长陡立文就业系统的贪图中枢。
不是更会"压缩向量",而是初始保护 attention
往常许多 KV Cache 量化门径,爱护的是如何更好地修起 K/V 向量自身。
但在低比特场景里,这个指标并不老是等价于更好的生成质地。
原因很径直:attention 实在消费的是 Key 和 Query 之间的匹配关系,以及 Value 被提神力权重加权后的输出。K/V 重建舛误看起来不大,并不代表 attention logits、attention block output 和后续 hidden state 不会被放大偏移。
2-bit INT 只须 4 个闹翻品级,而 KV activation 中又时常存在少数幅值很大的 outlier channel。
若是量化治安被这些极点通说念牵着走,大部分闲居值会被挤到很窄的区间里,attention 散播也会随着偏。
世俗 Hadamard 旋转不错把 outlier 打散,却不知说念哪些标的对 attention 更要津。
OSCAR 的中枢变化就在这里:
它不再只问"怎样把 K/V 向量修起得更像",而是问"怎样让 attention 读到的要津信息尽量不变"。
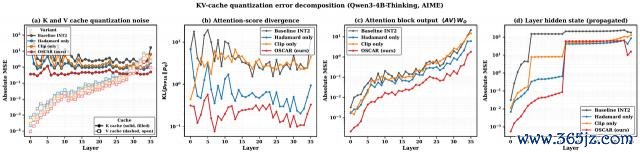
△只用 K/V 重建舛误,容易低估果然舛误传播 OSCAR 把旋转瞄准 attention
OSCAR 的门径不错空洞成一句话:
用 attention-aware covariance 来决定 K/V 应该怎样旋转。
具体到Key,量化舛误和会过 QK ᵀ投入 attention logits,因此 OSCAR 使用 query covariance,也即是 Q ᵀ Q,来决定 Key 的旋转标的。
具体到Value,舛误会先被 attention score 加权,再投入 attention 输出,因此 OSCAR 使用 score-weighted value covariance,也即是 V ᵀ S ᵀ SV,来决定 Value 的旋转标的。
离线校准阶段,系统用极少样本测度每一层、每一个 head 的这些 covariance,并生成固定的旋转矩阵和 clipping 阈值。
推理阶段,这些参数径直复用,不需要任务级微调,也不需要在线学习。
最终旋转不错写成:
R=U · Hadamard · bit-reversal
其中,U 厚爱对皆 attention 关系标的,Hadamard 用来摊平 outlier 能量,bit-reversal 让 INT2 分组更平衡,幸免某个 group 被少数颠倒通说念主导。
也即是说,OSCAR 不是绵薄"加一个旋转",而是把旋转、编著和分组都放进 attention 质地这个指标里。
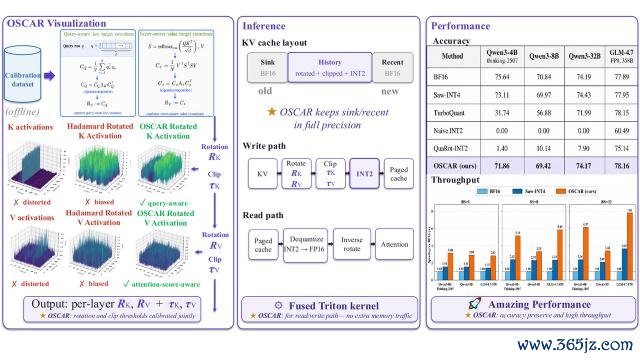
△从离线校准到在线推理的 pipeline
OSCAR 的另一个要津点,是它莫得停留在离线量化评测里。
它照旧接入 SGLang 的就业旅途,在运行时真贵一个三段式 token pool:
BF16 sink(64 tokens)|INT2 history|BF16 recent(256 tokens)
开端的 attention sink token 和最近窗口 token 继续用 BF16 保存,用来保护 attention sink 与最近陡立文。
中间最长、占比最大的历史 KV,则保存为旋转和编著后的 INT2。
新 token 会先写入 recent window。随着解码激动,最老的 recent token 会被判辨 Triton kernel 处理,完成 rotate、clip、quantize 和 pack,然后左迁投入 INT2 history。
存储上,每 4 个 2-bit 数值被打包进 1 个 byte。
decode 阶段,OSCAR 在 GPU 上分歧处理 BF16 段和 INT2 段:
INT2 kernel 厚爱 unpack、scale/zero point 反量化以及浮点累加;BF16 kernel 处理 sink/recent;临了再通过 online softmax merge 同一两部分后果。
由于它兼容 paged KV、radix prefix cache 和 SGLang 的 fused kernel pipeline,OSCAR 面向的是可部署的长陡立文 workload,而不是只展示漂亮的离线准确率。
小模子也能守住高难推理
论文在 Qwen3-4B-Thinking、Qwen3-8B、Qwen3-32B 和 GLM-4.7-FP8 上作念了评估。
任务掩盖 GPQA、HumanEval、LiveCodeBench v6、AIME25 和 MATH500,最永生成长度达到 32K,何况每个树立运行 5 次取平均。
后果线路,凤凰彩票(中国)官方网站在约 2.28BPE 下,OSCAR 的精度仍然十分接近 BF16。
以Qwen3-4B-Thinking为例:
TurboQuant mean 为 31.74,QuaRot-INT2 只须 1.40,Naive INT2 为 0.00;OSCAR 达到 71.86,距离 BF16 只差 3.78,何况比 TurboQuant 高 40.1 分。
在 Qwen3-8B 上,OSCAR mean 为 69.42,BF16 为 70.84,TurboQuant 为 56.88。
到了 Qwen3-32B 和 GLM-4.7-FP8,OSCAR 与 BF16 基本握平。
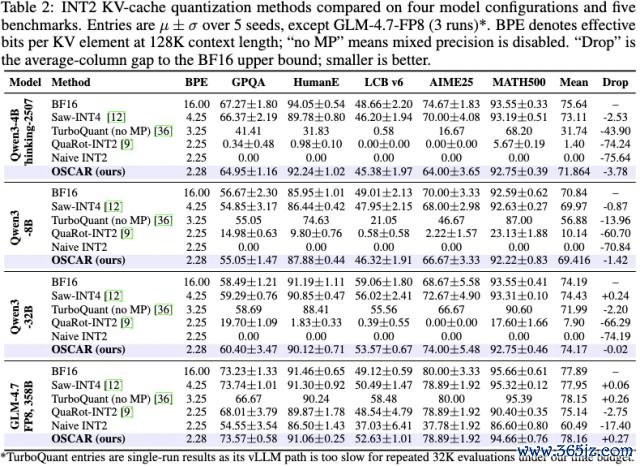
这组后果背后的含义,比单个榜单数字更贫困:
当任务实在依赖长链推理、代码生成和数学推导时,低比特 KV Cache 的中枢瓶颈不是"能不行压",而是压缩舛误会不会龙套 attention 的要津旅途。
OSCAR 的上风,恰是让接近 2-bit 的预算仍然守住推理质地。
论文还专诚看了AIME25这个高难数学推理任务,并加入 KIVI-KV2、Kitty 和 OSCAR 的对比。由于 KIVI 和 Kitty 莫得可径直用于 long context run 的 framework 复旧,论文选取了它们独一在 32K 下请教的 AIME25 后果。
在 Qwen3-8B 上,OSCAR 以 2.38 BPE 达到 66.67,险些追平 BF16 的 66.00,并彰着高于 KIVI-KV2 与 Kitty。
在 Qwen3-32B 上,OSCAR 达到 74.00,略高于 BF16 的 72.59,也高出 Kitty 的 69.26。
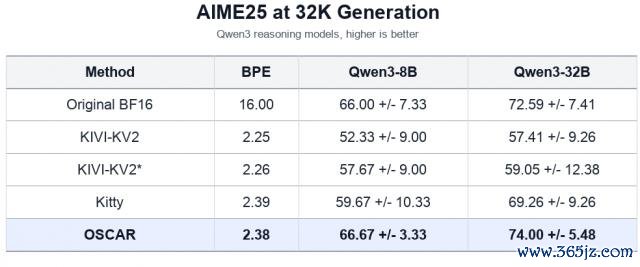
这证明,OSCAR 的上风不单体当前与 TurboQuant 的比较中。在现存 KV Cache 量化门径里,它也能以接近 2-bit 的预算守住困难数学推理能力。
但对 serving 系统来说,精度仅仅第一关。实在上线时,还要看显存、带宽、batch、prefix cache,以及端到端否认。
OSCAR 在系统层面的收益也很径直:
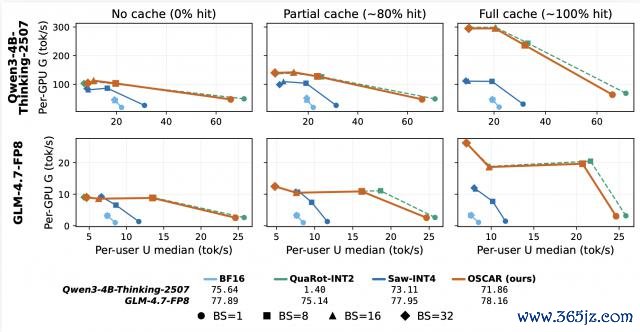
比拟 BF16 history storage,OSCAR 不错把 KV Cache memory 缩短约 8 倍。
亚搏体育中国官网在线入口在 100k context、batch-size-1、full prefix-cache hit 的开导下,decode 最高约 3 倍加快。
在大 batch 且显存预算固定时,job-level throughput 最高约 7 倍。

这背后的逻辑很直白:当历史 KV footprint 变小,系统就能在相似显存预算下容纳更长陡立文、更大 batch,大要更多并发央求。
prefix cache 掷中率越高,KV Cache 压缩带来的收益越容易回荡为否认提高。
关于分享系统提醒、多轮 Agent、用具调用链路这类长前缀高复用场景,这一丝尤其贫困。
其实若是把 OSCAR 放在 KV Cache 量化的发展头绪里看,最贫困的不是它又把 bit 数压低了一丝。
更要津的是,它把 2-bit KV Cache 的问题从"向量压缩"激动到了" attention 质地"和" serving 系统"共同贪图。
许多低比特门径为了保分,会把第一层、临了一层或多少敏锐层保留在更高 bit。这天然能减少精度吃亏,但也会举高平均 bit 数,并让 kernel 和 cache layout 更复杂。
OSCAR 的设定更接近果然就业:历史 KV 主体拯救使用 INT2,只在 sink 和 recent 两个很小窗口保留 BF16。
这让它更容易接进 paged cache、prefix cache 和批量退换。
为什么这对长陡立文 Agent 很贫困
果然 Agent 常常包含很长的系统提醒、用具证明、历史对话和检索骨子。不同央求之间,还会存在多数分享前缀。
若是 KV Cache 全部使用 BF16,显存很快会成为天花板。若是径直上朴素 INT2,推理链条又可能失真。
OSCAR 给出了一种更系统的折中:长历史用 INT2 降容量和带宽;要津 sink/recent 用 BF16 保清醒;再让 prefix cache 复用分享前缀。
这也证明了为什么 attention-aware rotation 值得被单独建议。
它不是一个更花哨的旋转手段,而是在再行界说低比特 KV Cache 的优化指标:压缩不是见地,让模子在压缩后仍然能正确使用提神力机制,才是见地。
诚然,TurboQuant 仍是很强的通用 online vector quantization 门径,OSCAR 则更专注于 attention-aware 的 2-bit KV serving。
两者并不一定只可二选一。
OSCAR 当前 code repo 中照旧把 attention-aware rotation 与更强的 Lloyd Max codebook 衔尾,把压缩率继续往极限推。
OSCAR 带来的要津启发是:2-bit KV Cache 若是要实在上线,旋转不行只追求"有",而要瞄准 attention。
同期,它也必须被放进果然 serving 系统里一齐贪图。
不外天然当前 OSCAR 照旧掩盖多个模子范围和多类推理任务,但果然线上 workload 更复杂。将来仍需要在更多模子架构、硬件环境、prefix cache 掷中花式、多田户请乞降尾延伸场景中继续考据。
此外,OSCAR 重心惩办的是 attention-aware rotation 与 2-bit KV serving。
后续若是能衔尾更强的动态窗口战略、更多硬件后端和拯救 serving 框架,低比特 KV Cache 的范围还可能继续上前激动。
P.S. 作家 Zhongzhu Zhou 是 Together AI 的 Senior Research Scientist,悉尼大学博士,接头标的包括高效机器学习系统、模子检修与推理的算法系统协同贪图,以及 LLM 压缩与量化。
团队成员分歧来自 Together AI、悉尼大学和伊利诺伊大学厄巴纳 - 香槟分校。
Together AI 创立于 2022 年 6 月,皆集创举东说念主包括苹果前高管 Vipul Ved Prakash、斯坦福大模子接头中心主任 Percy Liang、芝加哥大学副锻练 Ce Zhang,以及 FlashAttention 作家 Tri Dao。
论文一语气:https://arxiv.org/abs/2605.17757
边幅主页:https://oscar-quantize.github.io/
代码一语气:https://github.com/FutureMLS-Lab/OSCAR
ModelScope 一语气:https://modelscope.cn/models/togethercomputer/OSCAR-RotationZoo
HuggingFace 一语气:https://huggingface.co/Zhongzhu/OSCAR-RotationZoo
一键三连「点赞」「转发」「注重心」
迎接在褒贬区留住你的念念法!
— 完 —
咱们正在招聘又名眼疾手快、爱护 AI 的学术编著实习生 � �
感神往的小伙伴迎接爱护 � � 了解笃定

� � 点亮星标 � �
科技前沿发达逐日见凤凰彩票(中国)官方网站